Les Transformers sont devenus l’une des architectures les plus puissantes et populaires dans le domaine de l’apprentissage automatique, principalement grâce à leur succès spectaculaire dans des tâches liées au traitement du langage naturel (NLP), telles que la traduction automatique, la génération de texte, et la compréhension du langage. Cependant, ces dernières années, les Transformers ont également fait une entrée remarquée dans le domaine de la vision par ordinateur, révolutionnant des applications telles que la reconnaissance d’objets, la segmentation d’images, et l’analyse d’images.
Dans cet article, nous explorerons les Transformers pour la vision, leur fonctionnement, et comment ils sont appliqués pour améliorer les performances des modèles de vision par ordinateur.
Qu’est-ce qu’un Transformer ?
Un Transformer est une architecture de réseau de neurones introduite dans l’article “Attention is All You Need” par Vaswani et al. (2017). Le Transformer repose principalement sur un mécanisme appelé Attention, qui permet au modèle de se concentrer sur différentes parties d’une entrée (par exemple, des mots ou des pixels) de manière non séquentielle, contrairement aux architectures classiques comme les Réseaux de Neurones Récurrents (RNNs) ou les LSTMs.
Le Transformer est basé sur deux principaux composants :
- L’encodeur : Ce composant traite l’entrée, apprend des représentations des différentes parties de l’entrée, et les convertit en vecteurs.
- Le décodeur : Il génère la sortie en utilisant les représentations apprises par l’encodeur.
Le cœur de l’architecture Transformer repose sur le mécanisme d’attention qui permet au modèle de peser l’importance des différentes parties de l’entrée à chaque étape du processus d’apprentissage.
L’Adaptation des Transformers pour la Vision
L’application des Transformers à la vision par ordinateur est rendue possible grâce à l’idée de traiter des images comme une séquence de patches (petits blocs) plutôt que comme une grille de pixels. Cette approche permet d’appliquer directement le mécanisme d’attention des Transformers sur des images de manière plus efficace.
Les Transformers pour la vision ont été introduits sous la forme de modèles tels que Vision Transformer (ViT) et DEtection Transformer (DETR). Ces modèles se sont révélés particulièrement efficaces pour des tâches complexes de vision par ordinateur, souvent surpassant les architectures traditionnelles basées sur des réseaux de neurones convolutifs (CNNs).
Vision Transformer (ViT)
Le Vision Transformer (ViT) est un modèle qui utilise directement la structure Transformer pour les tâches de classification d’images. Voici les principales étapes de fonctionnement de ViT :
- Découpage de l’Image : Une image est divisée en plusieurs patches carrés (par exemple, de 16×16 pixels), et chaque patch est aplati en un vecteur de caractéristiques unidimensionnel.
- Embedding de Patchs : Chaque patch est transformé en un vecteur d’embedding, comme les tokens dans un modèle de langage.
- Positionnal Encoding : Comme les Transformers traitent des données non séquentielles, un encodage positionnel est ajouté à chaque patch pour fournir des informations sur la position relative des patches dans l’image.
- Mécanisme d’Attention : Les patchs sont ensuite traités par le mécanisme d’attention, qui apprend à lier des informations pertinentes entre eux, indépendamment de leur position dans l’image.
- Classification : Après avoir passé l’image à travers plusieurs couches d’encodeurs Transformer, la sortie d’un vecteur spécifique est utilisée pour effectuer la classification de l’image.
ViT a montré des résultats impressionnants, surpassant les CNNs traditionnels lorsque des données suffisantes sont disponibles pour l’entraînement, comme sur les grands ensembles de données (par exemple, ImageNet).
DEtection Transformer (DETR)
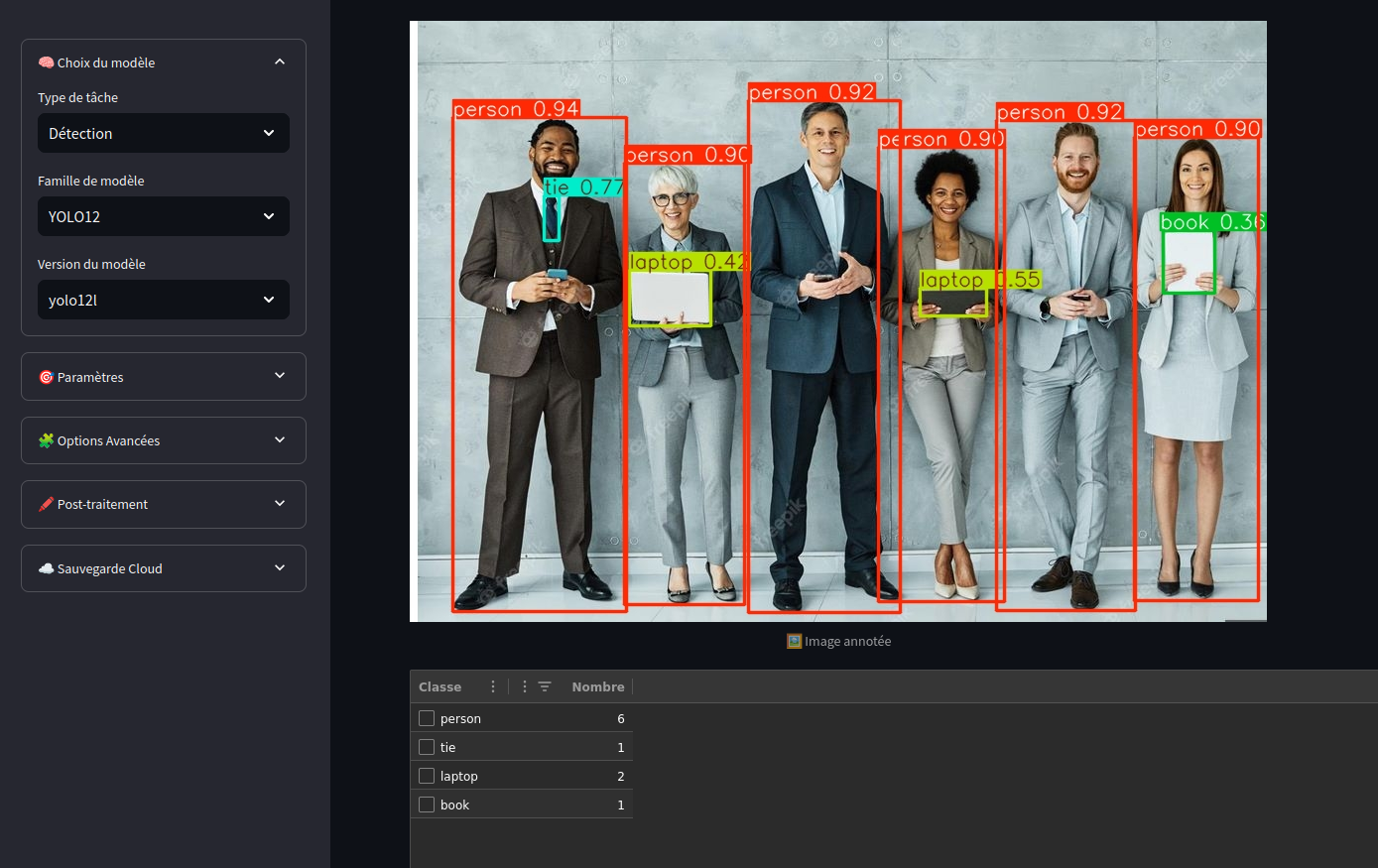
Le DEtection Transformer (DETR) est une extension du Transformer utilisée spécifiquement pour la détection d’objets. Contrairement aux approches traditionnelles, qui dépendent de régions proposées et de classificateurs, DETR utilise une approche end-to-end dans laquelle l’encodeur Transformer traite directement l’image et l’architecture de décodeur génère des prédictions de boîtes englobantes (bounding boxes) et de classes d’objets.
Les principales caractéristiques de DETR sont les suivantes :
- Encodage de l’image : Comme dans ViT, l’image est découpée en patches et encodée dans un espace de caractéristiques à l’aide du Transformer.
- Mécanisme d’Attention : Le mécanisme d’attention permet à DETR de capturer les relations spatiales entre les objets dans l’image, ce qui est essentiel pour la détection précise des objets.
- Prédictions de Boîtes Englobantes et de Classes : Contrairement aux méthodes classiques qui génèrent d’abord des propositions d’objets, DETR génère directement les prédictions des objets en une seule étape, réduisant ainsi la complexité du processus.
- Post-traitement : Après avoir généré des prédictions, des étapes de filtrage sont effectuées pour éliminer les détections redondantes et peu fiables.
DETR a surpassé les approches classiques de détection d’objets dans de nombreux cas, avec une efficacité accrue et une capacité à généraliser à de nouvelles scènes.
Avantages des Transformers pour la Vision
Les Transformers pour la vision présentent plusieurs avantages par rapport aux architectures CNN traditionnelles :
- Capacité à capturer des dépendances globales : Contrairement aux CNNs, qui sont limités à des zones locales de l’image, le mécanisme d’attention des Transformers permet de capturer des relations à longue portée entre les pixels ou les patches, ce qui est particulièrement utile pour des tâches complexes comme la segmentation et la détection d’objets.
- Architecture flexible et modulaire : L’architecture Transformer peut être facilement adaptée pour une variété de tâches, y compris la classification, la segmentation, la détection d’objets, et même la vidéo. Cela permet de développer des modèles plus généralisés et réutilisables pour plusieurs applications.
- End-to-end learning : Les modèles Transformer peuvent être entraînés de manière end-to-end, ce qui simplifie l’optimisation et améliore la performance par rapport aux méthodes traditionnelles basées sur plusieurs étapes (comme la génération de propositions d’objets).
- Scalabilité : Les Transformers se prêtent bien aux modèles à grande échelle. ViT, par exemple, a montré qu’il peut surpasser les CNNs sur de grands ensembles de données, et des versions encore plus grandes peuvent être utilisées pour des applications complexes.
Inconvénients et Défis
Malgré leurs avantages, les Transformers pour la vision ont également certains défis et inconvénients :
- Besoins en données massives : Les Transformers, notamment ViT, nécessitent de grandes quantités de données pour bien fonctionner. Lorsqu’ils sont formés sur des ensembles de données relativement petits, leur performance peut être inférieure à celle des CNNs.
- Calcul intensif : Les Transformers sont généralement plus gourmands en ressources computationnelles que les CNNs, car le mécanisme d’attention nécessite une grande quantité de mémoire et de calculs pour chaque pair de pixels (ou patches).
- Sensibilité à la taille des images : Comme les Transformers traitent des patches, la résolution des images peut avoir un impact direct sur la performance des modèles. La gestion de différentes résolutions peut être un défi.
Applications des Transformers pour la Vision
Les Transformers ont montré leur efficacité dans une variété d’applications de vision par ordinateur, notamment :
- Reconnaissance d’objets : Des modèles comme ViT et DETR sont utilisés pour classer des objets et localiser leurs positions dans des images.
- Segmentation d’images : Les Transformers, tels que le SegFormer, sont utilisés pour diviser les images en régions significatives, ce qui est essentiel pour des applications comme la reconnaissance d’organes dans l’imagerie médicale.
- Analyse vidéo : Les Transformers peuvent également être appliqués aux séquences vidéo pour comprendre les relations temporelles entre les objets dans une scène, ce qui est utile dans des domaines comme la surveillance, la conduite autonome, et l’analyse d’événements sportifs.
Conclusion
Les Transformers ont ouvert de nouvelles perspectives pour la vision par ordinateur, permettant de surpasser les modèles traditionnels comme les CNNs dans certaines tâches complexes. Grâce à leur capacité à capturer des relations globales et leur flexibilité, les Transformers, comme ViT et DETR, sont devenus des modèles de référence pour des applications allant de la classification d’images à la détection d’objets et la segmentation. Cependant, ils viennent avec des défis en termes de besoin en données et en ressources computationnelles. Néanmoins, leur adoption continue de croître, et leur potentiel reste vaste dans l’évolution future de la vision par ordinateur.