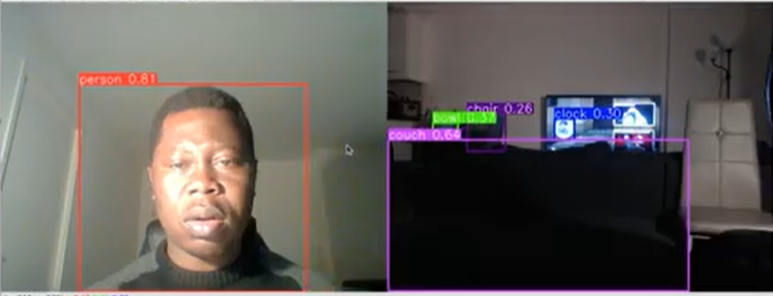
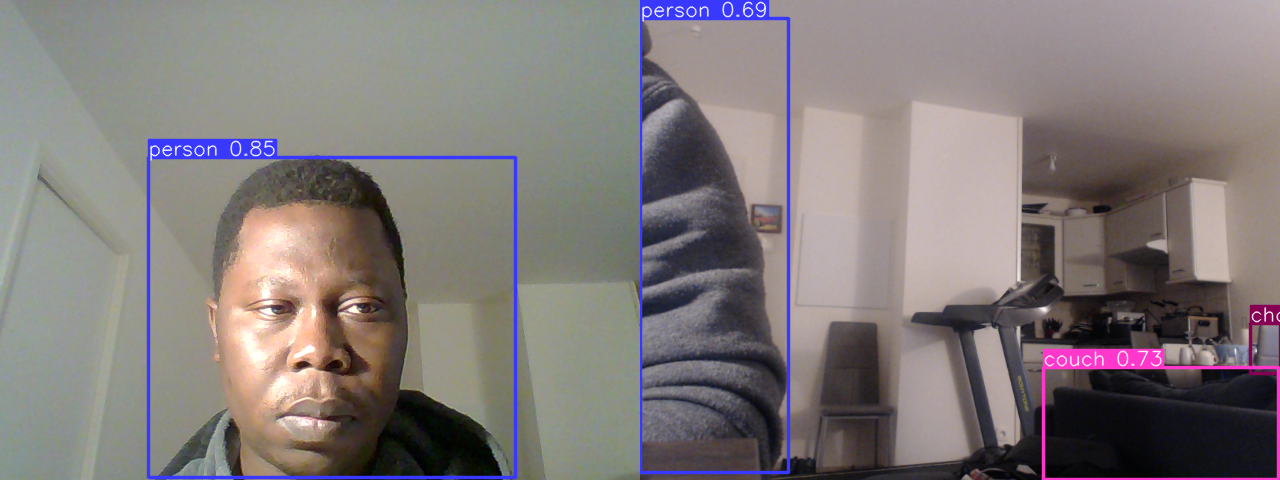
La classification d’objets est un processus qui consiste à identifier et à classer les objets dans une image. Elle est utilisée dans de nombreux domaines, tels que la vision par ordinateur, la reconnaissance d’images et l’analyse d’images.
Il existe deux approches principales à la classification d’objets : la classification supervisée et la classification non supervisée.
Classification supervisée
La classification supervisée nécessite un ensemble de données d’entraînement, qui comprend des images avec des objets déjà identifiés. Le modèle de classification est ensuite entraîné sur cet ensemble de données, en apprenant à identifier les caractéristiques qui distinguent les différents objets.
Classification non supervisée
La classification non supervisée ne nécessite pas d’ensemble de données d’entraînement. Le modèle de classification est ensuite entraîné sur un ensemble de données d’images, en apprenant à identifier les groupes d’objets qui présentent des caractéristiques similaires.
Méthodes de classification d’objets
Il existe de nombreuses méthodes différentes de classification d’objets. Les méthodes les plus courantes sont les suivantes :
- Apprentissage automatique
L’apprentissage automatique est une approche qui utilise des algorithmes pour apprendre automatiquement à partir de données. Les méthodes d’apprentissage automatique les plus courantes pour la classification d’objets sont les réseaux de neurones convolutifs (CNN), les forêts aléatoires et les k-moyennes.
- Apprentissage statistique
L’apprentissage statistique est une approche qui utilise des modèles statistiques pour représenter les données. Les méthodes d’apprentissage statistique les plus courantes pour la classification d’objets sont la régression logistique et la classification bayésienne.
- Apprentissage en profondeur
L’apprentissage en profondeur est une approche qui utilise des réseaux neuronaux complexes pour apprendre des données. Les méthodes d’apprentissage en profondeur les plus courantes pour la classification d’objets sont les réseaux de neurones convolutifs (CNN).
Applications de la classification d’objets
La classification d’objets est utilisée dans de nombreux domaines, tels que :
La vision par ordinateur est un domaine de l’intelligence artificielle qui vise à permettre aux ordinateurs de voir et de comprendre le monde qui les entoure. La classification d’objets est une technique importante de vision par ordinateur, qui est utilisée pour identifier les objets dans des images et des vidéos.
La reconnaissance d’images est un domaine de l’intelligence artificielle qui vise à identifier des objets ou des personnes dans des images. La classification d’objets est une technique importante de reconnaissance d’images, qui est utilisée pour identifier les objets présents dans une image.
L’analyse d’images est un domaine de l’intelligence artificielle qui vise à extraire des informations d’images. La classification d’objets est une technique importante d’analyse d’images, qui est utilisée pour identifier les objets présents dans une image et pour extraire des informations sur ces objets.
Exemples de classification d’objets
Voici quelques exemples de classification d’objets :
- Identifier les voitures dans une image de circulation
- Identifier les personnes dans une image de foule
- Identifier les produits dans une image de magasin
- Identifier les lésions cutanées dans une image médicale
- Identifier les plantes dans une image de champ
La classification d’objets est une technique puissante qui peut être utilisée dans de nombreux domaines. Elle est en constante évolution, avec de nouvelles méthodes et de nouveaux algorithmes qui sont développés chaque année.