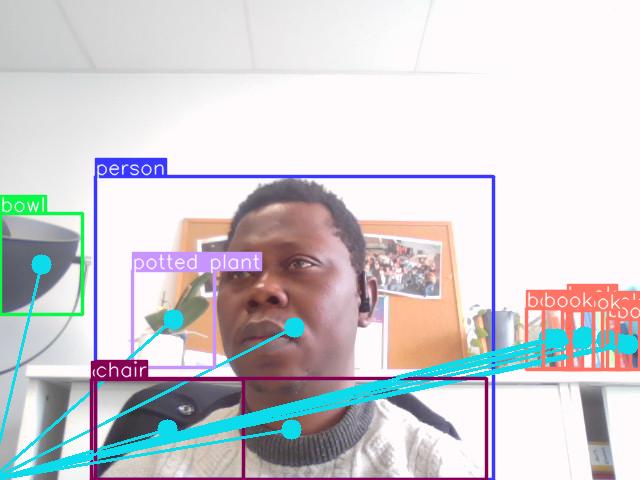
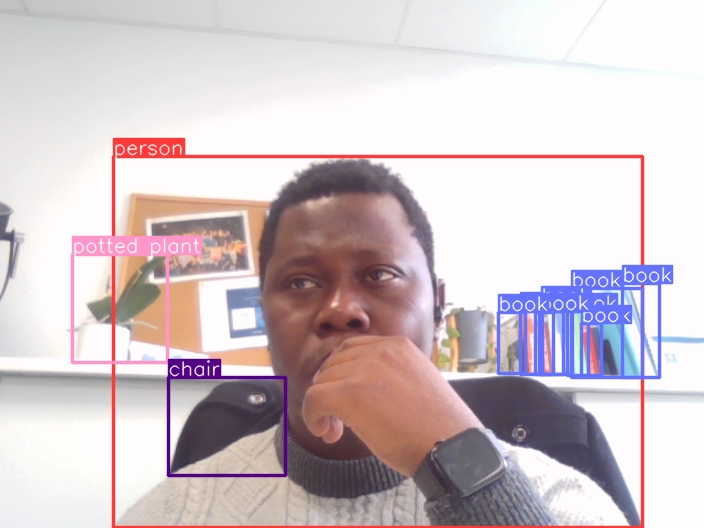
Zero-shot object detection
La détection d’objets sans apprentissage préalable (en anglais: zero-shot object detection) est un domaine de la vision par ordinateur qui permet de détecter des objets dans des images sans avoir entraîné le modèle au préalable sur ces objets spécifiques. En termes plus simples, cela permet à un modèle d’identifier et de localiser des objets dans une image même s’il n’a jamais vu ces objets auparavant.
Voici un résumé des points clés :
- Pas de données d’entraînement requises : Contrairement aux méthodes traditionnelles de détection d’objets qui nécessitent des ensembles de données massifs avec des objets étiquetés, les modèles sans apprentissage supervisé fonctionnent sans aucune donnée d’entraînement visuelle pour une classe d’objet spécifique.
- Requête textuelle pour la détection : Ces modèles s’appuient sur des descriptions textuelles ou des invites pour comprendre quels objets rechercher dans une image. Par exemple, vous pouvez fournir une invite comme “chat” et le modèle essaiera de trouver tous les chats dans l’image.
- Concentration sur les objets invisibles : L’idée principale est de détecter des objets sur lesquels le modèle n’a pas été entraîné auparavant. Cela le rend utile dans les scénarios où l’étiquetage de grands ensembles de données n’est pas pratique ou lorsque vous souhaitez identifier une large gamme d’objets sans avoir à entraîner un modèle personnalisé pour chacun.
Voici quelques applications de la détection d’objets sans apprentissage supervisé :
- Compter les objets dans les entrepôts ou les magasins
- Gérer la foule lors d’événements
- Identifier des espèces nouvelles ou rares dans des études écologiques
- Annotation d’images pour des tâches telles que la recherche d’images
Cependant, il est important de noter que la détection d’objets sans apprentissage supervisé est un domaine en constante évolution. Cette approche présente des limitations :
- Précision : Étant donné que le modèle n’a pas vu d’objets spécifiques pendant l’entraînement, la précision peut être inférieure à celle des méthodes traditionnelles de détection d’objets.
- Gamme d’objets limitée : Ces modèles pourraient ne pas être capables de détecter toutes les classes d’objets possibles.
Dans l’ensemble, la détection d’objets sans apprentissage supervisé offre une approche prometteuse pour identifier des objets invisibles dans les images. À mesure que la technologie évolue, on peut s’attendre à des améliorations de la précision et à une applicabilité plus large.