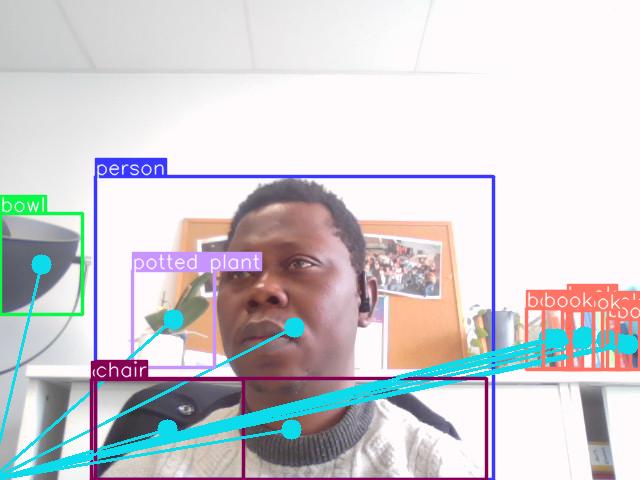
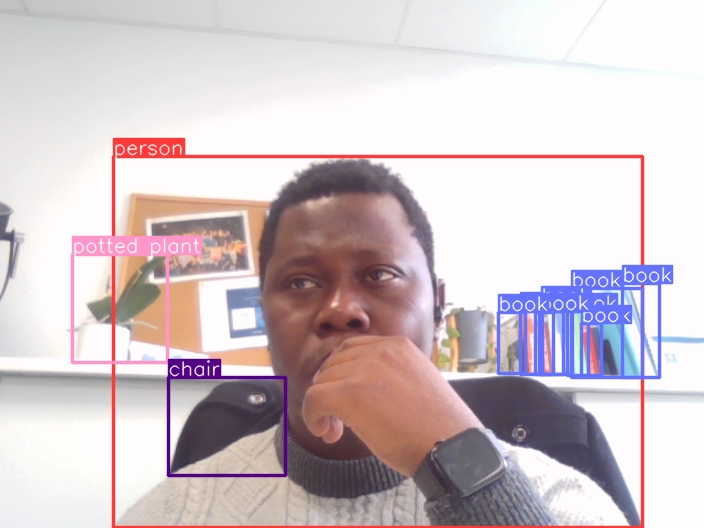
La détection d’objets en temps réel est une tâche cruciale dans de nombreuses applications de vision par ordinateur, telles que la conduite autonome, la surveillance et l’imagerie médicale. YOLOv10, la dernière version de la série de réseaux neuronaux YOLO (You Only Look Once), repousse les limites de la précision et de l’efficacité dans ce domaine. Dans cet article, nous explorons les fonctionnalités et les avantages de YOLOv10, qui le positionnent comme un outil puissant et innovant pour la communauté de la vision par ordinateur.
Nouveautés de YOLOv10
YOLOv10 introduit plusieurs innovations techniques pour améliorer tant la précision que la vitesse de traitement. Parmi ces améliorations, on trouve généralement :
- Architecture améliorée : YOLOv10 continue d’optimiser son architecture de réseau de neurones, souvent en affinant les couches, les connexions et la manière dont les caractéristiques sont extraites et traitées.
- Utilisation de techniques avancées : L’intégration de techniques d’apprentissage profond plus avancées, comme l’attention ou des convolutions améliorées, permet d’accroître la précision tout en maintenant ou en améliorant la vitesse.
- Optimisation des performances : Des améliorations en termes de traitement parallèle ou d’utilisation de matériel spécifique peuvent être implémentées pour rendre le modèle plus rapide et plus efficace sur diverses plates-formes.
- Meilleure généralisation : Les versions antérieures ont parfois été critiquées pour leur incapacité à généraliser à partir d’ensembles de données limités ou biaisés. YOLOv10 cherche à améliorer cela grâce à une meilleure technique d’entraînement et à une augmentation des données plus sophistiquée.
Architecture
YOLOv10 est basé sur une architecture novatrice qui intègre plusieurs innovations clés, notamment :
- Bloc de convolution compact : un bloc de convolution qui remplace les couches de convolution traditionnelles.
- Downsampling spatial-channel : un module de downsampling qui réduit les dimensions spatiales des cartes de caractéristiques tout en augmentant les dimensions de canal.
- Tête de détection v10 : une tête de détection qui prédit les boîtes de délimitation des objets, les classes et les confiances.
Performances et efficacité
YOLOv10 se concentre sur l’amélioration des performances et de l’efficacité, offrant une détection d’objets en temps réel de pointe. Par rapport à ses prédécesseurs, YOLOv10 présente des améliorations significatives en termes de post-traitement et d’architecture de modèle. Les expériences extensives démontrent que YOLOv10 atteint des performances et une efficacité de pointe dans diverses échelles de modèles.
Par exemple, YOLOv10-S est 1,8 fois plus rapide que RT-DETR-R18 tout en offrant des performances similaires sur le jeu de données COCO. De plus, il nécessite 2,8 fois moins de paramètres et de FLOPs. De même, YOLOv10-B présente une latence inférieure de 46 % et 25 % de paramètres en moins par rapport à YOLOv9-C pour des performances identiques.
Variantes de modèle
YOLOv10 propose une gamme de variantes de modèle, chacune adaptée à des exigences d’application spécifiques. Les variantes incluent YOLOv10-N, YOLOv10-S, YOLOv10-M, YOLOv10-B, YOLOv10-L et YOLOv10-X. Chaque variante offre un équilibre différent entre vitesse et précision, permettant aux utilisateurs de choisir le modèle le plus adapté à leurs besoins.
Comparaisons
YOLOv10 surpasse également les versions précédentes de YOLO. Par exemple, YOLOv10-L et YOLOv10-X dépassent YOLOv8-L et YOLOv8-X de 0,3 AP et 0,5 AP, respectivement, tout en réduisant le nombre de paramètres de 1,8 fois et 2,3 fois. Ces améliorations témoignent de l’engagement continu de l’équipe YOLO à améliorer les performances et l’efficacité du modèle.
Cas d’utilisation
YOLOv10 trouve de nombreuses applications dans divers domaines. Il peut être utilisé pour la détection d’objets en temps réel dans des scénarios de conduite autonome, permettant une prise de décision rapide et précise. De plus, il peut être utilisé dans les systèmes de surveillance pour détecter et suivre des objets ou des personnes d’intérêt. De plus, YOLOv10 peut être appliqué à l’imagerie médicale pour identifier des anomalies ou des caractéristiques spécifiques dans les images radiologiques.
Conclusion
YOLOv10 représente une avancée significative dans le domaine de la détection d’objets en temps réel, offrant à la fois des performances et une efficacité de pointe. Sa gamme de variantes de modèle et ses améliorations architecturales en font un outil polyvalent et puissant pour les chercheurs et les professionnels de la vision par ordinateur. Avec son potentiel d’impact dans divers domaines, YOLOv10 continue de faire progresser l’état de l’art dans le domaine de la vision par ordinateur.