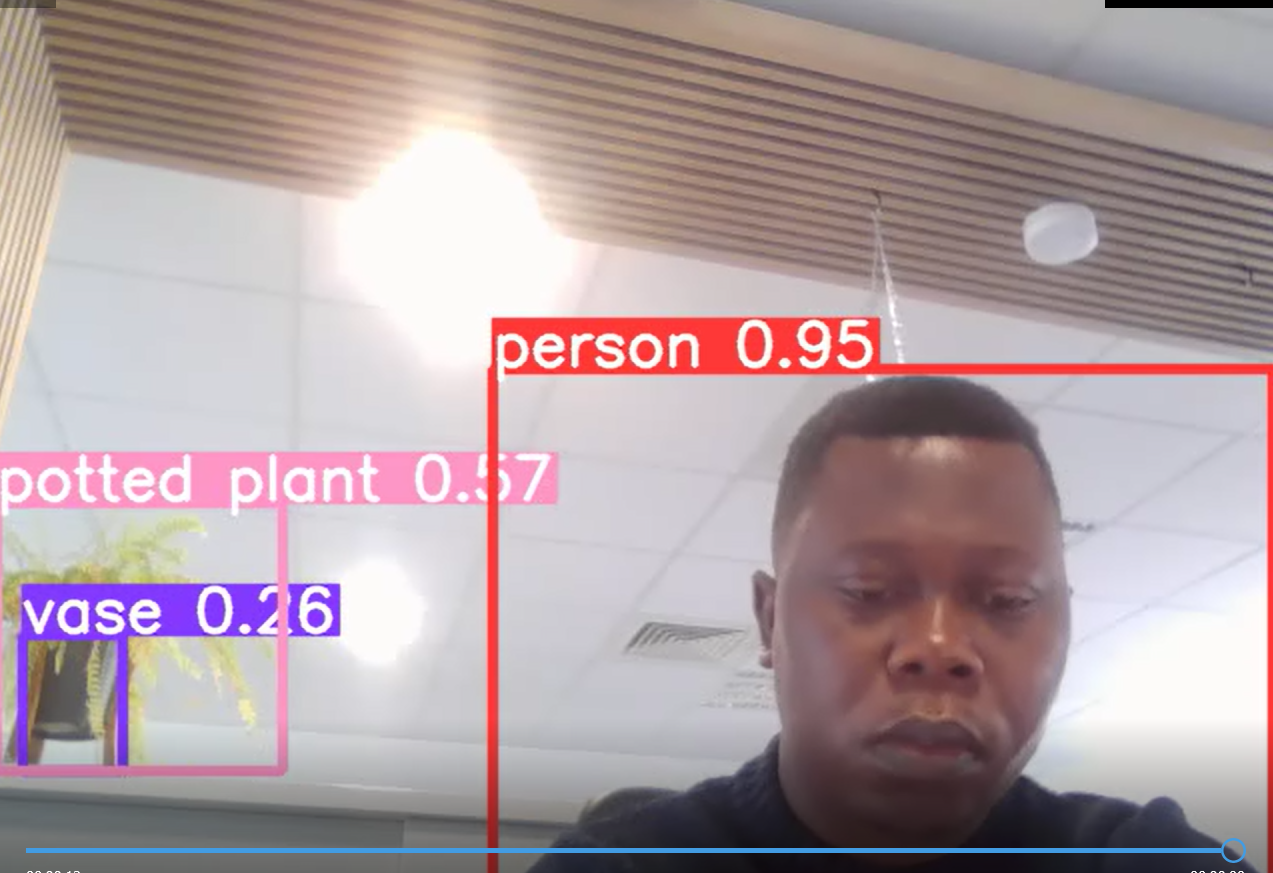
Detection d’objet avec yolov5

Découvrez yolov5 et la détection d’objet ===
La détection d’objet est une technologie qui a profondément révolutionné la surveillance et la sécurité dans les domaines de l’industrie, de la santé, de l’automobile et de la sécurité publique. Yolov5 est l’une des technologies de détection d’objet les plus puissantes et les plus récentes disponibles sur le marché. Dans cet article, nous allons explorer les avantages, les applications, les défis et les limites de cette technologie, ainsi que son avenir dans le domaine de la reconnaissance visuelle.
Comment yolov5 détecte-t-il les objets ?
Yolov5 utilise un réseau de neurones convolutionnels pour détecter les objets dans une image. Le réseau est entraîné sur de grandes quantités de données d’image pour apprendre à reconnaître les caractéristiques des différents objets. Le réseau divise ensuite l’image en grilles et calcule les probabilités de présence d’un objet dans chacune de ces grilles. Ensuite, il détermine les boîtes de délimitation qui entourent l’objet et calcule les probabilités de chaque catégorie d’objet.
Les avantages de yolov5 pour la détection d’objet
Les avantages de yolov5 pour la détection d’objet sont nombreux. Tout d’abord, il est extrêmement rapide et précis, ce qui le rend idéal pour les applications en temps réel telles que la surveillance vidéo et la conduite autonome. De plus, il peut détecter plusieurs objets dans une seule image, ce qui est utile pour la surveillance de zones à forte densité de population, comme les stades et les gares. Enfin, yolov5 est très flexible et peut être utilisé pour détecter une grande variété d’objets, de la nourriture aux voitures en passant par les personnes.
Yolov5 : une technologie en constante évolution
La technologie yolov5 est en constante évolution. Des mises à jour sont régulièrement publiées pour améliorer la précision et la vitesse de la détection d’objet. En outre, de nouveaux ensembles de données sont constamment ajoutés pour permettre à la technologie de reconnaître de nouveaux types d’objets.
Comment entraîner yolov5 pour la détection d’objet
Pour entraîner yolov5, il faut d’abord collecter des données d’image et les annoter avec des boîtes de délimitation pour chaque objet. Ensuite, ces données doivent être transformées en un format compréhensible pour yolov5, puis le réseau doit être entraîné sur ces données à l’aide d’une carte graphique puissante.
Les différentes applications de yolov5
Les applications de yolov5 sont nombreuses et diverses. Les domaines de la surveillance, de la sécurité publique et de la conduite autonome font partie des domaines d’application les plus prometteurs. La reconnaissance et l’analyse d’images médicales sont également des domaines où yolov5 peut être utile. Enfin, la détection de la nourriture et la reconnaissance d’objet pour les robots de livraison sont des applications en pleine croissance.
Yolov5 : la solution pour la sécurité et la surveillance
Yolov5 est particulièrement adapté à la sécurité et à la surveillance, car il peut détecter rapidement et précisément les objets dans une image en temps réel. Il peut être utilisé pour la surveillance de zones à forte densité de population, la détection d’activités suspectes et la reconnaissance de plaques d’immatriculation.
Les challenges de la détection d’objet avec yolov5
La détection d’objet avec yolov5 peut rencontrer des challenges tels que la détection d’objets de petite taille ou la reconnaissance d’objets très similaires. Il peut également y avoir des problèmes avec l’occlusion, lorsque les objets sont partiellement bloqués par d’autres objets.
Les limites de yolov5 dans la détection d’objet
Bien que yolov5 soit une technologie de pointe pour la détection d’objet, il y a des limites à ce qu’il peut faire. Par exemple, il peut avoir des difficultés à reconnaître les objets dans des conditions de faible luminosité ou lorsque les objets sont flous. Il peut également ne pas être en mesure de détecter des objets très petits ou très éloignés.
Yolov5 vs les autres technologies de détection d’objet
Yolov5 est souvent comparé à d’autres technologies de détection d’objet telles que Faster R-CNN et Mask R-CNN. Bien que ces technologies soient également très puissantes, yolov5 se distingue par sa vitesse et sa flexibilité. Il est également capable de détecter plusieurs objets dans une seule image.
Yolov5 et l’avenir de la reconnaissance visuelle
Yolov5 représente l’avenir de la reconnaissance visuelle, avec des avancées régulières en termes de précision et de vitesse. À l’avenir, il sera probablement utilisé dans de nombreux domaines, y compris la sécurité, la médecine, l’automobile, et la robotique.
Yolov5 : la clé pour une reconnaissance d’objet rapide et précise ===
En conclusion, yolov5 est une technologie de pointe pour la détection d’objet qui présente de nombreux avantages pour la surveillance, la sécurité publique et la conduite autonome. Bien que des challenges et des limites existent, yolov5 reste une solution impressionnante pour la reconnaissance visuelle. Nous pouvons nous attendre à ce que yolov5 continue d’évoluer et de s’améliorer dans les années à venir, ouvrant ainsi la voie à de nouvelles applications passionnantes.